DBT
Data Warehousing
- There have been multiple modeling paradigms since the advent of database technology. Many of these are classified as normalized modeling.
- Normalized modeling techniques were designed when storage was expensive and computational power was not as affordable as it is today.
- With a modern cloud-based data warehouse, we can approach analytics differently in an agile or ad hoc modeling technique. This is often referred to as denormalized modeling.
- dbt can build your data warehouse into any of these schemas. dbt is a tool for how to build these rather than enforcing what to build. dbt removes DDL and DML ..
- DDL (Data Definition Language)/DML (Data Manipulation Language)/DQL (Data Query Language)
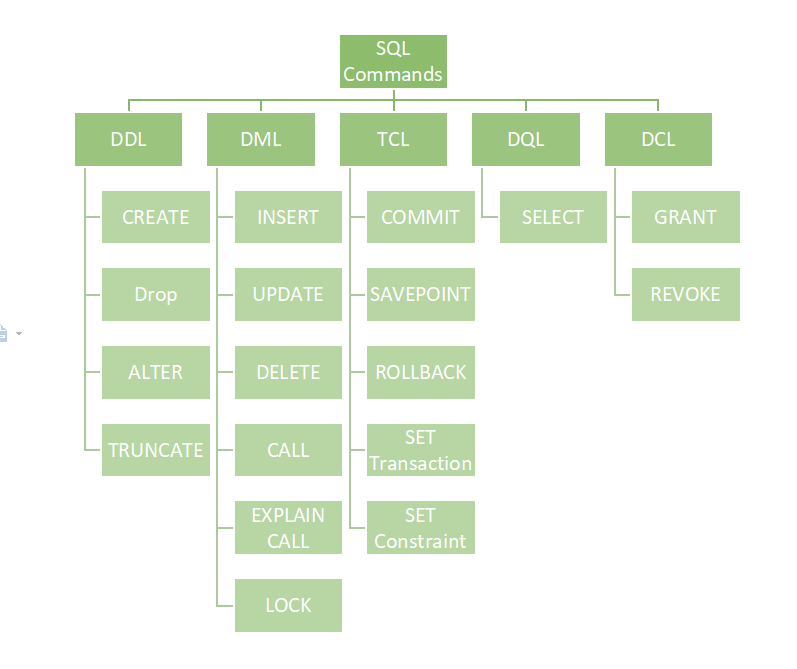
- Kimball, Inmon, and Data Vault are three popular methodologies used in data warehousing, each with its own approach and principles.
- Kimball Methodology:
- Developed by Ralph Kimball, this methodology focuses on building data warehouses using a dimensional modeling approach.
- It emphasizes the creation of star schemas or snowflake schemas for organizing data into facts (measurable events) and dimensions (descriptive attributes).
- Kimball’s approach is more bottom-up, meaning it starts with identifying business processes and building data marts that serve specific business functions.
- It emphasizes simplicity, agility, and business user accessibility.
- The Kimball methodology is more suited for smaller to medium-sized data warehousing projects.
- Inmon Methodology:
- Created by Bill Inmon, this methodology advocates for the construction of a centralized data warehouse known as the “Corporate Information Factory” (CIF).
- Inmon’s approach focuses on the normalization of data before it’s loaded into the data warehouse, aiming to reduce redundancy and ensure data consistency.
- It emphasizes a top-down approach, starting with integrating all data into a single, enterprise-wide data model before creating data marts.
- The Inmon methodology prioritizes data integration and consistency across the entire organization.
- It’s often considered more suitable for large enterprises with complex data integration needs.
- Data Vault:
- Data Vault is a methodology developed by Dan Linstedt, focusing on the construction of a flexible, scalable, and auditable data warehousing architecture.
- It employs a hub-and-spoke architecture, where raw data (hubs) are connected through relationships (links) and descriptive metadata (satellites).
- Data Vault modeling enables easy scalability and adaptability to changing business requirements, making it suitable for agile environments.
- It emphasizes historical tracking of data changes, making it particularly useful for compliance and auditing purposes.
- Data Vault is often seen as a hybrid approach, complementing either Kimball or Inmon methodologies, or even used standalone.
DBT
dbt is an open-source command line tool that helps analysts and engineers transform data in their warehouse more effectively. dbt is a SQL-first transformation workflow that lets teams quickly and collaboratively deploy analytics code following software engineering best practices like modularity, portability, CI/CD, and documentation. Now anyone on the data team can safely contribute to production-grade data pipelines.
DBT viewpoint
The landscape of analytics has evolved, with a shift towards modular and collaborative solutions comprising data integration tools, analytic databases, programming languages like SQL, R, Python, and visualization tools. Despite this progress, analytics teams face challenges in delivering high-quality, timely analyses due to workflow inefficiencies such as isolated operations, redundant work, and inconsistent methodologies. Drawing parallels from software engineering practices, there’s a call to adopt collaborative features in analytics workflows, including version control, quality assurance, documentation, and modularity. Additionally, recognizing analytic code as a valuable asset, emphasis is placed on protecting and enhancing investments through features like multiple environments, service level guarantees, design for maintainability, and automated tools to streamline workflows. The vision is to establish an open set of tools and processes to facilitate efficient and effective analytics operations.
DBT Fundamentals
Traditional Data Teams
- Data engineers are responsible for maintaining data infrastructure and the ETL process for creating tables and views.
- Data analysts focus on querying tables and views to drive business insights for stakeholders.
ETL vs ELT
- ETL (extract transform load) is the process of creating new database objects by extracting data from multiple data sources, transforming it on a local or third party machine, and loading the transformed data into a data warehouse.
- ELT (extract load transform) is a more recent process of creating new database objects by first extracting and loading raw data into a data warehouse and then transforming that data directly in the warehouse.
- The new ELT process is made possible by the introduction of cloud-based data warehouse technologies.

Analytics Engineering
- Analytics engineers focus on the transformation of raw data into transformed data that is ready for analysis. This new role on the data team changes the responsibilities of data engineers and data analysts.
- Data engineers can focus on larger data architecture and the EL in ELT.
- Data analysts can focus on insight and dashboard work using the transformed data.
- Note: At a small company, a data team of one may own all three of these roles and responsibilities. As your team grows, the lines between these roles will remain blurry.
Models
- Models are .sql files that live in the models folder.
- Models are simply written as select statements - there is no DDL/DML that needs to be written around this. This allows the developer to focus on the logic.
- After constructing a model, dbt run in the command line will actually materialize the models into the data warehouse. The default materialization is a view.
- The materialization can be configured as a table with the following configuration block at the top of the model file:
{{ config(
materialized='table'
) }}
- The same applies for configuring a model as a view:
{{ config(
materialized='view'
) }}
- When dbt run is executing, dbt is wrapping the select statement in the correct DDL/DML to build that model as a table/view. If that model already exists in the data warehouse, dbt will automatically drop that table or view before building the new database object.
version: 2
models:
- name: <model_name>
columns:
- name: <column_name>
data_type: <string>
description: <markdown_string>
quote: true | false
tests: ...
tags: ...
meta: ...
- name: <another_column>
...
Modularity
- We could build each of our final models in a single model as we did with
dim_customers, however with dbt we can create our final data products using modularity. - Modularity is the degree to which a system’s components may be separated and recombined, often with the benefit of flexibility and variety in use.
- This allows us to build data artifacts in logical steps.
- For example, we can stage the raw customers and orders data to shape it into what we want it to look like. Then we can build a model that references both of these to build the final
dim_customersmodel. - Thinking modularly is how software engineers build applications. Models can be leveraged to apply this modular thinking to analytics engineering.
ref Macro
- Models can be written to reference the underlying tables and views that were building the data warehouse (e.g.
analytics.dbt_jsmith.stg_customers). This hard codes the table names and makes it difficult to share code between developers. - The ref function allows us to build dependencies between models in a flexible way that can be shared in a common code base. The ref function compiles to the name of the database object as it has been created on the most recent execution of dbt run in the particular development environment. This is determined by the environment configuration that was set up when the project was created.
- Example:
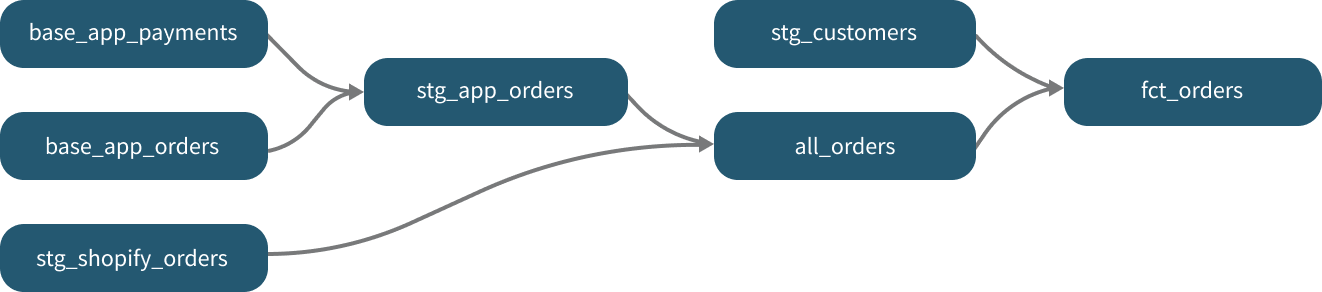
{{ ref('stg_customers') }}compiles toanalytics.dbt_jsmith.stg_customers. - The ref function also builds a lineage graph like the one shown below. dbt is able to determine dependencies between models and takes those into account to build models in the correct order.

Naming Conventions
- Sources (src) refer to the raw table data that have been built in the warehouse through a loading process.
- Staging (stg) refers to models that are built directly on top of sources. These have a one-to-one relationship with sources tables. These are used for very light transformations that shape the data into what you want it to be. These models are used to clean and standardize the data before transforming data downstream. Note: These are typically materialized as views.
- Intermediate (int) refers to any models that exist between final fact and dimension tables. These should be built on staging models rather than directly on sources to leverage the data cleaning that was done in staging.
- Fact (fct) refers to any data that represents something that occurred or is occurring. Examples include sessions, transactions, orders, stories, votes. These are typically skinny, long tables.
- Dimension (dim) refers to data that represents a person, place or thing. Examples include customers, products, candidates, buildings, employees.
Project Organization
- When dbt run is executed, dbt will automatically run every model in the models directory.
- The subfolder structure within the models directory can be leveraged for organizing the project as the data team sees fit.
- This can then be leveraged to select certain folders with dbt run and the model selector.
- Example: If
dbt run -s stagingwill run all models that exist in models/staging. - Marts folder: All intermediate, fact, and dimension models can be stored here. Further subfolders can be used to separate data by business function (e.g. marketing, finance)
- Staging folder: All staging models and source configurations can be stored here. Further subfolders can be used to separate data by data source (e.g. Stripe, Segment, Salesforce). (We will cover configuring Sources in the Sources module)

Sources
- Sources represent the raw data that is loaded into the data warehouse.
- We can reference tables in our models with an explicit table name (
raw.jaffle_shop.customers). - However, setting up Sources in dbt and referring to them with the source function enables a few important tools.
- Multiple tables from a single source can be configured in one place.
- Sources are easily identified as green nodes in the Lineage Graph.
- You can use dbt source freshness to check the freshness of raw tables.
- Sources are configured in YML files in the models directory.
version: 2
sources:
- name: <source_name>
tables:
- name: <table_name>
columns:
- name: <column_name>
description: <markdown_string>
data_type: <string>
quote: true | false
tests: ...
tags: ...
meta: ...
- name: <another_column>
...
- The ref function is used to build dependencies between models.
- Similarly, the source function is used to build the dependency of one model to a source.
- Given the source configuration above, the snippet
{{ source('jaffle_shop','customers') }}in a model file will compile to raw.jaffle_shop.customers. - The Lineage Graph will represent the sources in green.

- Freshness thresholds can be set in the YML file where sources are configured. For each table, the keys loaded_at_field and freshness must be configured.
version: 2
sources:
- name: jaffle_shop
database: raw
schema: jaffle_shop
tables:
- name: orders
loaded_at_field: _etl_loaded_at
freshness:
warn_after: {count: 12, period: hour}
error_after: {count: 24, period: hour}
- A threshold can be configured for giving a warning and an error with the keys
warn_afteranderror_after. - The freshness of sources can then be determined with the command
dbt sourcefreshness.
Seeds
version: 2
seeds:
- name: <seed_name>
columns:
- name: <column_name>
description: <markdown_string>
data_type: <string>
quote: true | false
tests: ...
tags: ...
meta: ...
- name: <another_column>
...
Snapshots
version: 2
snapshots:
- name: <snapshot_name>
columns:
- name: <column_name>
description: <markdown_string>
data_type: <string>
quote: true | false
tests: ...
tags: ...
meta: ...
- name: <another_column>
Analyses
version: 2
analyses:
- name: <analysis_name>
columns:
- name: <column_name>
description: <markdown_string>
data_type: <string>
- name: <another_column>
Testing
- Testing is used in software engineering to make sure that the code does what we expect it to.
- In Analytics Engineering, testing allows us to make sure that the SQL transformations we write produce a model that meets our assertions.
- In dbt, tests are written as select statements. These select statements are run against your materialized models to ensure they meet your assertions.
- In dbt, there are two types of tests - generic tests and singular tests
- Generic tests are written in YAML and return the number of records that do not meet your assertions. These are run on specific columns in a model.
- Singular tests are specific queries that you run against your models. These are run on the entire model.
- dbt ships with four built in tests: unique, not null, accepted values, relationships.
- Unique tests to see if every value in a column is unique
- Not_null tests to see if every value in a column is not null
- Accepted_values tests to make sure every value in a column is equal to a value in a provided list
- Relationships tests to ensure that every value in a column exists in a column in another model (see: referential integrity)
- Generic tests are configured in a YAML file, whereas singular tests are stored as select statements in the tests folder.
- Tests can be run against your current project using a range of commands
dbt test runs all tests in the dbt projectdbt test --select test_type:genericdbt test --select test_type:singulardbt test --select one_specific_model
Documentation
- Documentation is essential for an analytics team to work effectively and efficiently. Strong documentation empowers users to self-service questions about data and enables new team members to on-board quickly.
- Documentation often lags behind the code it is meant to describe. This can happen because documentation is a separate process from the coding itself that lives in another tool.
- Therefore, documentation should be as automated as possible and happen as close as possible to the coding.
- In dbt, models are built in SQL files. These models are documented in YML files that live in the same folder as the models.
- Documentation of models occurs in the YML files (where generic tests also live) inside the models directory. It is helpful to store the YML file in the same subfolder as the models you are documenting.
- For models, descriptions can happen at the model, source, or column level.
- If a longer form, more styled version of text would provide a strong description, doc blocks can be used to render markdown in the generated documentation.
- In the command line section, an updated version of documentation can be generated through the command dbt docs generate. This will refresh the
view docslink in the top left corner of the Cloud IDE. - The generated documentation includes the following:
- Lineage Graph
- Model, source, and column descriptions
- Generic tests added to a column
- The underlying SQL code for each model
- and more…
Source Properties
Source properties can be declared in any properties.yml file in your models/ directory (as defined by the model-paths config). Source properties are “special properties” in that you can’t configure them in the dbt_project.yml file or using config() blocks.
You can name these files whatever_you_want.yml, and nest them arbitrarily deeply in subfolders within the models/ directory:
dbt_project.yml
- Every dbt project needs a
dbt_project.ymlfile — this is how dbt knows a directory is a dbt project. It also contains important information that tells dbt how to operate your project. - By default, dbt will look for
dbt_project.ymlin your current working directory and its parents, but you can set a different directory using the--project-dirflag or theDBT_PROJECT_DIRenvironment variable. - you can’t set up a “property” in the
dbt_project.ymlfile if it’s not a config (an example is macros). This applies to all types of resources. - The following example is a list of all available configurations in the dbt_project.yml file:
name: string
config-version: 2
version: version
profile: profilename
model-paths: [directorypath]
seed-paths: [directorypath]
test-paths: [directorypath]
analysis-paths: [directorypath]
macro-paths: [directorypath]
snapshot-paths: [directorypath]
docs-paths: [directorypath]
asset-paths: [directorypath]
target-path: directorypath
log-path: directorypath
packages-install-path: directorypath
clean-targets: [directorypath]
query-comment: string
require-dbt-version: version-range | [version-range]
dbt-cloud:
project-id: project_id # Required
defer-env-id: environment_id # Optional
quoting:
database: true | false
schema: true | false
identifier: true | false
metrics:
<metric-configs>
models:
<model-configs>
seeds:
<seed-configs>
semantic-models:
<semantic-model-configs>
snapshots:
<snapshot-configs>
sources:
<source-configs>
tests:
<test-configs>
vars:
<variables>
on-run-start: sql-statement | [sql-statement]
on-run-end: sql-statement | [sql-statement]
dispatch:
- macro_namespace: packagename
search_order: [packagename]
restrict-access: true | false
Simple Jaffle Shop Project using DuckDB and DBT
- Create a new repo
- Create a virtual env
- Install
dbt coreand dbt adapter for duckdb - Initialize dbt with
dbt init - Go to profiles and replace duck db path as appropriate (
~/.dbt/profiles)
duck_dbt:
outputs:
dev:
type: duckdb
path: path/dev.duckdb
threads: 1
target: dev
- Check if dbt connection with database is working as expected using
dbt debug - Find the three csv files for Jaffle and place them in
seedsdirectory - Run
dbt seed - Remove the sample model code generated by dbt by default
- Create staging models
- Create analytics/common models
- Experiment other stuff
- Generate docs using
dbt docs generateand serve usingdbt docs serve
dbt_project.yml
# Name your project! Project names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models
name: 'duck_dbt'
version: '1.0.0'
config-version: 2
# This setting configures which "profile" dbt uses for this project.
profile: 'duck_dbt'
# These configurations specify where dbt should look for different types of files.
# The `model-paths` config, for example, states that models in this project can be
# found in the "models/" directory. You probably won't need to change these!
model-paths: ["models"]
analysis-paths: ["analyses"]
test-paths: ["tests"]
seed-paths: ["seeds"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]
clean-targets: # directories to be removed by `dbt clean`
- "target"
- "dbt_packages"
seeds:
duck_dbt:
+raw_customers:
+database: dev
+schema: raw
+raw_orders:
+database: dev
+schema: raw
+raw_payments:
+database: dev
+schema: raw
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the `{{ config(...) }}` macro.
models:
duck_dbt:
# Config indicated by + and applies to all files under models/example/
marts:
+database: dev
+enabled: true
+materialized: table
sales:
+schema: sales
+enabled: true
common:
+schema: common
+enabled: true
PSA
models/psa
version: 2
models:
- name: stg_customers
description: Staging layer for customer
columns:
- name: customer_id
description: unique id of the customer
tests:
- unique
- not_null
- name: first_name
description: first name of the customer
tests:
- not_null
- name: last_name
description: last name of the customer
tests:
- not_null
- name: stg_orders
description: Staging layer for orders
columns:
- name: order_id
description: unique id of the order
tests:
- unique
- not_null
- name: customer_id
description: id of the customer
tests:
- not_null
- relationships:
to: ref('stg_customers')
field: customer_id
- name: order_date
description: timestamp of order
tests:
- not_null
- name: order_status
description: status of the order
tests:
- accepted_values:
values:
["completed", "returned", "return_pending", "shipped", "placed"]
- name: stg_payments
description: Staging layer for payments
columns:
- name: payment_id
description: unique id of the payment
tests:
- unique
- not_null
- name: order_id
description: id of the order
tests:
- not_null
- relationships:
to: ref('stg_orders')
field: order_id
- name: payment_method
description: method of payment
tests:
- not_null
- name: amount
description: amount
tests:
- not_null
stg_customers.sql
{{ config(
materialized = 'view'
) }}
WITH customers AS (
SELECT
*
FROM
{{ ref('raw_customers') }}
),
FINAL AS (
SELECT
id AS customer_id,
first_name,
last_name
FROM
customers
)
SELECT
*
FROM
FINAL
stg_orders.sql
{{ config(
materialized = 'view'
) }}
WITH orders AS (
SELECT
*
FROM
{{ ref('raw_orders') }}
),
FINAL AS (
SELECT
id AS order_id,
user_id AS customer_id,
order_date,
status as order_status
FROM
orders
)
SELECT
*
FROM
FINAL
stg_payments.sql
{{ config(
materialized = 'view'
) }}
WITH payments AS (
SELECT
*
FROM
{{ ref('raw_payments') }}
),
FINAL AS (
SELECT
id AS payment_id,
order_id,
payment_method,
amount
FROM
payments
)
SELECT
*
FROM
FINAL
Fact and Dimension Tables
schema.yaml
models/marts/common/schema.yaml
version: 2
models:
- name: dim_customers
description: Dim layer for customer
columns:
- name: customer_id
description: unique id of the customer
tests:
- unique
- not_null
- name: first_name
description: first name of the customer
tests:
- not_null
- name: last_name
description: last name of the customer
tests:
- not_null
- name: dim_orders
description: Dim layer for orders
columns:
- name: order_id
description: unique id of the order
tests:
- unique
- not_null
- name: customer_id
description: id of the customer
tests:
- not_null
- name: order_date
description: timestamp of order
tests:
- not_null
- name: order_status
description: status of the order
tests:
- accepted_values:
values:
["completed", "returned", "return_pending", "shipped", "placed"]
- name: dim_payments
description: Dim layer for payments
columns:
- name: payment_id
description: unique id of the payment
tests:
- unique
- not_null
- name: order_id
description: id of the order
tests:
- not_null
- relationships:
to: ref('stg_orders')
field: order_id
- name: payment_method
description: method of payment
tests:
- not_null
- name: fact_payments
description: Fact layer for payments
columns:
- name: payment_id
description: unique id of the payment
tests:
- unique
- not_null
- name: order_id
description: id of the order
tests:
- not_null
- relationships:
to: ref('stg_orders')
field: order_id
- name: amount
description: amount
tests:
- not_null
dim_customers.sql
{{ config(
materialized = 'table'
) }}
WITH customers AS (
SELECT
*
FROM
{{ ref('stg_customers') }}
)
SELECT
*
FROM
customers
dim_orders.sql
{{ config(
materialized = 'table'
) }}
WITH orders AS (
SELECT
*
FROM
{{ ref('stg_orders') }}
)
SELECT
*
FROM
orders
dim_payments.sql
{{ config(
materialized = 'table'
) }}
WITH payments AS (
SELECT
*
FROM
{{ ref('stg_payments') }}
)
SELECT
payment_id,
order_id,
payment_method
FROM
payments
fact_payments.sql
{{ config(
materialized = 'table'
) }}
WITH payments AS (
SELECT
*
FROM
{{ ref('stg_payments') }}
)
SELECT
payment_id,
order_id,
amount
FROM
payments
DBT Commands Cheatsheet
- By default,
dbt runexecutes all of the models in the dependency graph;dbt seedcreates all seeds,dbt snapshotperforms every snapshot. The--selectflag is used to specify a subset of nodes to execute. - Select resources to build (run, test, seed, snapshot) or check freshness:
--select,-s - …. https://docs.getdbt.com/reference/node-selection/syntax
dbt generic commands
dbt init project_name
Performs several actions necessary to create a new dbt project.
dbt deps
Install the dbt dependencies from packages.yml file.
dbt clean
Removes the /dbt_modules (populated when you run deps) and /target folder (populated when models are run).
dbt run
Regular run. Will run all models based on hierarchy.
dbt run --full-refresh
Refreshes incremental models.
dbt test
Runs custom data tests and schema tests.
dbt seed
Loads CSV files specified in the data-paths directory into the data warehouse.
dbt compile
Compiles all models. This isn’t a command you will need to run regularly. dbt will compile the models when you run any models.
dbt snapshot
Executes all the snapshots defined in your project.
dbt clean
A utility function that deletes all folders specified in the clean-targets list specified in dbt_project.yml. It is useful for deleting the dbt_modules and target directories.
dbt debug
Ensures your connection, config file, and dbt dependencies are good.
dbt run threads 2
Runs all models in 2 threads and also overrides the threads in profiles.yml.
Running based on the model name
dbt run --models modelname
Will only run the specified modelname.
dbt run --models +modelname
Will run the specified modelname and all of its parent models.
dbt run --models modelname+
Will run the specified modelname and all of its child models.
dbt run --models +modelname+
Will run the specified modelname, and all of its parent and child models.
dbt run --models @modelname
Will run the specified modelname, all of its parent models, all of its child models, and all parents of its child models.
dbt run --exclude modelname
Will run all models except the specified modelname.
Running based on the folder name
dbt run --models folder
Will run all models in the specified folder.
dbt run --models folder.subfolder
Will run all models in the specified subfolder.
dbt run --models +folder.subfolder
Will run all models in the specified subfolder and all of its parent models.
dbt run --models folder.subfolder+
Will run all models in the specified subfolder and all of its child models.
dbt run --models +folder.subfolder+
Will run all models in the specified subfolder, all of its parent models, and all of its child models.
dbt run --models @folder.subfolder
Will run all models in the specified subfolder, all of its parent models, all of its child models, and all parents of its child models.
dbt run --exclude folder
Will run all models except those in the specified folder.
Running based on tag
dbt run -m tag:tagname
Will run only models tagged with the specified tagname.
dbt run -m +tag:tagname
Will run models tagged with the specified tagname and all of their parent models.
dbt run -m tag:tagname+
Will run models tagged with the specified tagname and all of their child models.
dbt run -m +tag:tagname+
Will run models tagged with the specified tagname, all of their parent models, and all of their child models.
dbt run -m @tag:tagname
Will run models tagged with the specified tagname, all of their parent models, all of their child models, and all parents of their child models.
dbt run --exclude tag:tagname
Will run all models except those tagged with the specified tagname.
dbt test -m tag:tagname
Will run tests only for models tagged with the specified tagname.
dbt test -m +tag:tagname
Will run tests for models tagged with the specified tagname and all of their parent models.
dbt test -m tag:tagname+
Will run tests for models tagged with the specified tagname and all of their child models.
dbt test -m +tag:tagname+
Will run tests for models tagged with the specified tagname, all of their parent models, and all of their child models.
dbt test -m @tag:tagname
Will run tests for models tagged with the specified tagname, all of their parent models, all of their child models, and all parents of their child models.
dbt test --exclude tag:tagname
Will run tests for all models except those tagged with the specified tagname.
Multiple model inputs in dbt command
dbt run -m modelname+ folder @tag:tagname modelname
Specifies a list of models to run, including modelname and all of its children, models in the folder, models tagged with tagname, and modelname itself.
dbt run --exclude modelname folder tag:tagname modelname
Specifies a list of models to exclude from running, including modelname, models in the folder, and models tagged with tagname.