[Paper Exploration] In-Depth Analysis of the Segment Anything Model (SAM)
Authors: Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, Ross Girshick
Published on 2023
The Segment Anything Model (SAM) was developed by Meta AI as a foundation model for image segmentation tasks. The goal of SAM is to create a universal model that can efficiently handle various segmentation tasks with minimal prompting.

Abstract
We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks. We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive – often competitive with or even superior to prior fully supervised results. We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images at this https URL to foster research into foundation models for computer vision.
1. Problem Formulation
In image segmentation, the task is to partition an image into different regions or objects. Mathematically, given an image $I \in \mathbb{R}^{H \times W \times 3}$, where $H$ and $W$ are the height and width, the goal is to generate a mask $M \in {0,1}^{H \times W}$ for each object or region.
Segment Anything Objective:
The objective of SAM is to generalize across diverse segmentation tasks, where the input can be various forms of prompts: text, points, bounding boxes, or even free-form scribbles. The task then is to predict the segmentation mask based on these prompts.
Let the input image be $I$, and the prompt $P$, the segmentation mask is predicted by:
$$ M = f(I, P; \theta) $$
Where $f$ is the SAM model, parameterized by $\theta$, that predicts the mask $M$ given the image $I$ and prompt $P$.
2. SAM Architecture
Encoder:
SAM’s encoder is a deep neural network that takes the input image $I$ and processes it into a feature map representation $F$. This can be expressed as:
$$ F = \text{Encoder}(I; \theta_{enc}) $$

The encoder uses a Vision Transformer (ViT), which is particularly well-suited for handling large and diverse datasets because of its attention-based mechanism. The ViT splits the image into patches and applies self-attention:
-
Patch embedding: Divide the input image $I$ into $N$ patches, each of size $P \times P$:
$$ I \rightarrow {P_1, P_2, …, P_N} $$
-
Self-attention mechanism: Each patch is embedded into a fixed-dimensional latent space $Z \in \mathbb{R}^{N \times D}$, where $D$ is the embedding dimension:
$$ Z = \text{softmax}\left(\frac{Q K^T}{\sqrt{d}}\right) V $$
where $Q, K, V$ are the query, key, and value matrices computed from the patch embeddings, and $d$ is a scaling factor to normalize the dot products.
Prompt Interaction:
Given the feature map $F$, the prompt $P$ is projected into the same latent space. Let $P_{\text{latent}}$ be the prompt embedding:
$$ P_{\text{latent}} = \text{Embed}(P; \theta_{P}) $$
The interaction between $F$ and $P_{\text{latent}}$ is learned via cross-attention mechanisms. The cross-attention operation can be written as:
$$ \text{CrossAttn}(F, P_{\text{latent}}) = \text{softmax}\left(\frac{F P_{\text{latent}}^T}{\sqrt{d}}\right) P_{\text{latent}} $$
Decoder:
The decoder takes the refined feature map $F’$ from the encoder and the prompt interaction to produce the final segmentation mask. This is done by upscaling the latent features back to the image resolution. Mathematically:
$$ M = \text{Decoder}(F’, P_{\text{latent}}; \theta_{dec}) $$
3. Loss Function
SAM is trained using a combination of loss functions to ensure both pixel-wise accuracy and boundary precision. The typical losses used are:
-
Cross-Entropy Loss:
Used for pixel-wise classification:$$ L_{\text{CE}} = - \sum_{i,j} M_{i,j} \log(\hat{M}_{i,j}) $$
where $\hat{M}_{i,j}$ is the predicted mask probability for pixel $(i, j)$.
-
Dice Loss:
Focuses on the overlap between the predicted and ground-truth masks:$$ L_{\text{Dice}} = 1 - \frac{2 \sum M \cdot \hat{M}}{\sum M + \sum \hat{M}} $$
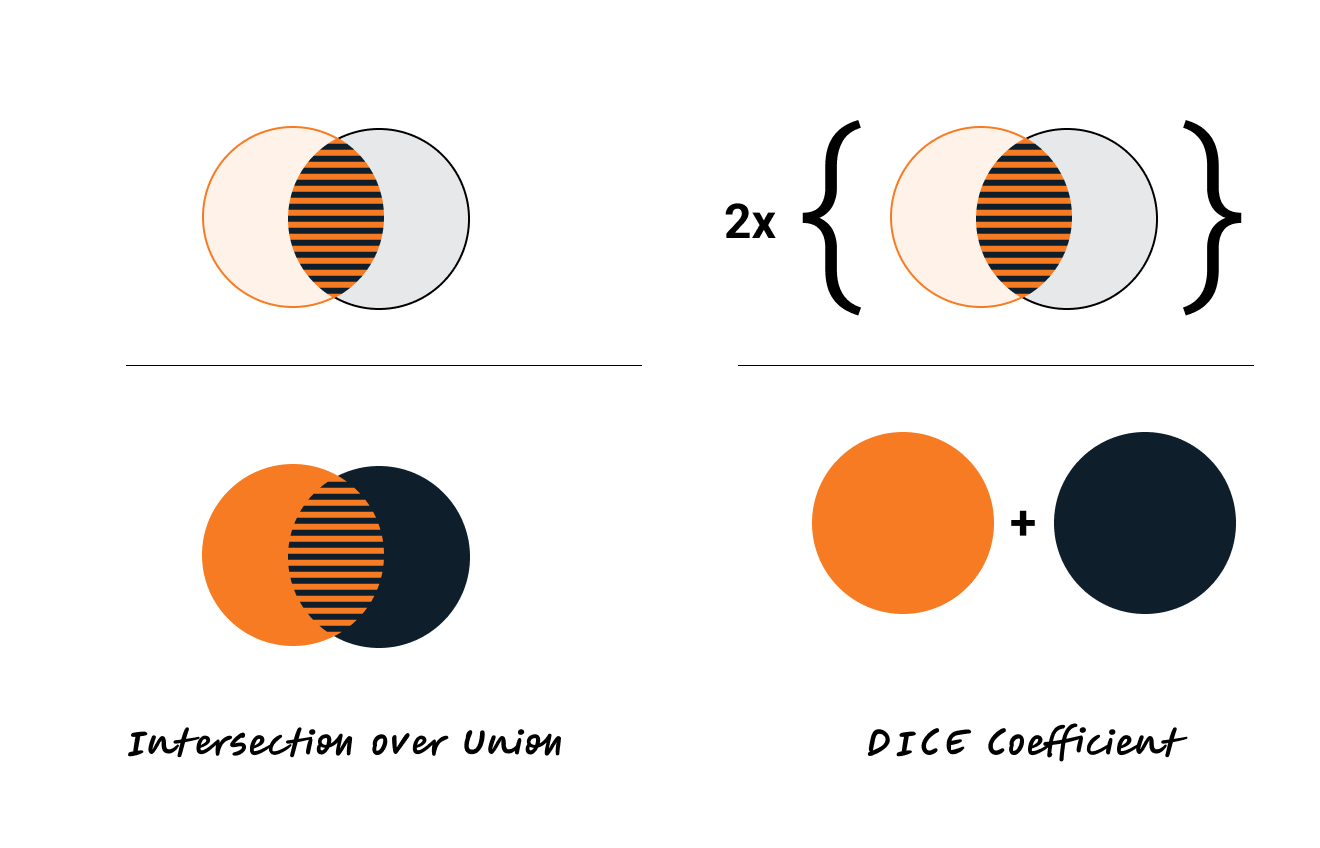
The relationship between IoU and the Dice coefficient can be expressed as:
$$ \text{Dice} = \frac{2 \times \text{IoU}}{1 + \text{IoU}} $$
where,
$$\text{IoU} = \frac{|A \cap B|}{|A \cup B|}$$
-
Total Loss:
The total loss function combines both:$$ L = L_{\text{CE}} + \lambda L_{\text{Dice}} $$
Task, Model, and Data Engine
The successful implementation of the Segment Anything Model (SAM) relies on a well-defined framework encompassing the task, the model architecture, and the underlying data engine. Each component plays a crucial role in the overall performance and applicability of SAM across various segmentation tasks.
1. Task

The primary task of SAM is to perform image segmentation, which involves partitioning an image into distinct segments or regions that correspond to different objects or parts within the image. The versatility of SAM allows it to tackle a wide range of segmentation tasks, including but not limited to:

- Semantic Segmentation: Classifying each pixel in the image into a predefined category, providing a global understanding of the scene.
- Instance Segmentation: Distinguishing between different instances of the same object category, enabling the model to identify and segment individual objects separately.
- Panoptic Segmentation: A combination of semantic and instance segmentation that provides a comprehensive representation of the scene, identifying both object categories and individual instances.
SAM’s design allows it to adapt to these tasks with minimal prompting, making it a powerful tool for various applications.
2. Model
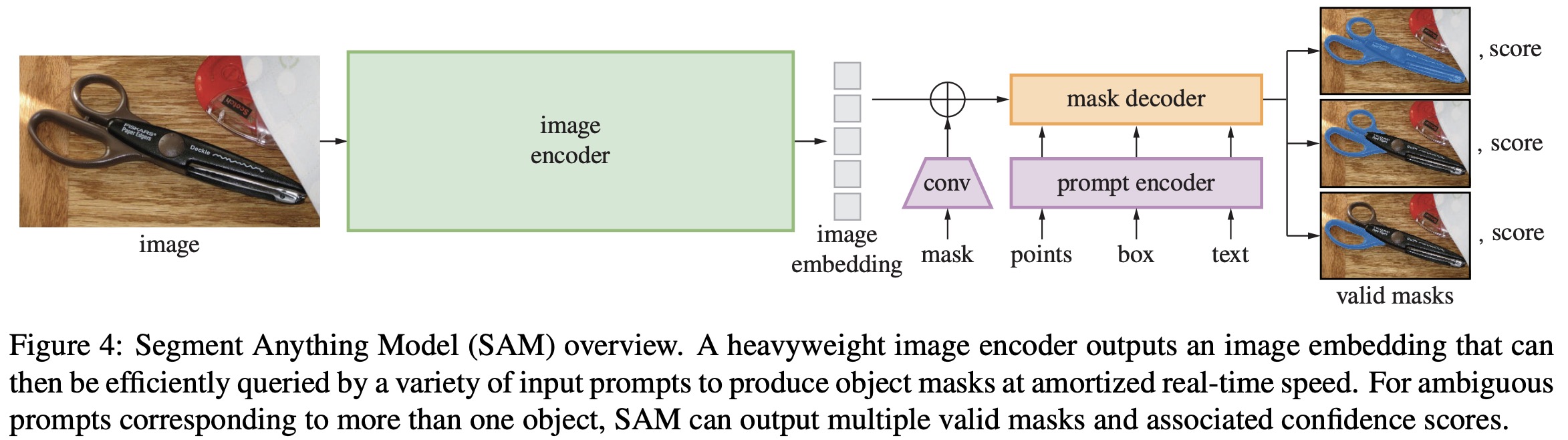
The SAM architecture is a sophisticated model built on the principles of foundation models and Vision Transformers (ViTs). Key characteristics of the SAM model include:
- Pre-trained Architecture: SAM is trained on a large dataset (SA-1B) that encompasses diverse images and segmentation tasks, allowing it to generalize effectively across various domains.
- Prompt-based Segmentation: SAM leverages user-provided prompts (such as points, bounding boxes, or text) to guide the segmentation process, facilitating a more interactive and flexible user experience.
- Scalability: The model’s architecture is designed to scale efficiently, accommodating various image sizes and complexities without significant degradation in performance.
The combination of these features makes SAM an efficient and adaptable model for image segmentation tasks.
3. Data Engine
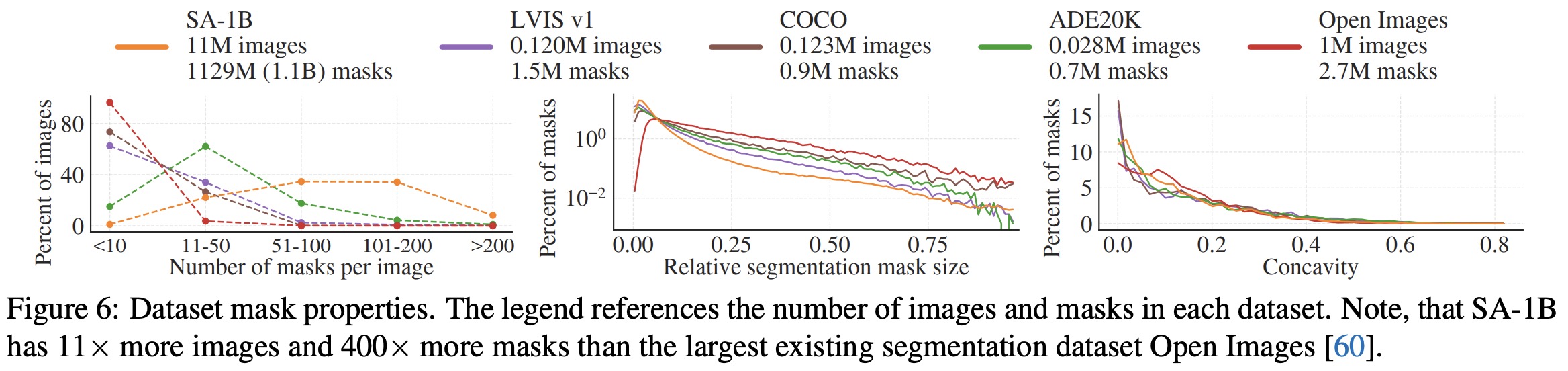
The data engine plays a critical role in the training and evaluation of SAM. It encompasses the following aspects:
- Dataset Quality: The performance of SAM is significantly influenced by the quality and diversity of the training dataset. The SA-1B dataset, consisting of over a billion segmented masks, provides a rich source of information for training the model on various objects and scenes.
- Data Preprocessing: Effective data preprocessing techniques (e.g., normalization, augmentation) are essential to enhance the robustness of the model. These techniques help improve the model’s performance by ensuring it can handle variations in input data.
- Evaluation Metrics: Establishing clear evaluation metrics is vital for assessing the performance of SAM across different segmentation tasks. Common metrics include Intersection over Union (IoU), pixel accuracy, and F1 score, which provide insights into the model’s effectiveness and areas for improvement.
Together, the task, model, and data engine form a cohesive framework that enhances the functionality and effectiveness of the Segment Anything Model, allowing it to address a wide array of segmentation challenges.
Appendix: Extended Terminologies
1. Foundation Models
Foundation models are large, pre-trained models that can be fine-tuned for various downstream tasks. These models are typically trained on massive datasets, allowing them to generalize across tasks without being explicitly trained on each.
Let $D_{\text{pretrain}}$ represent the large pre-training dataset and $\theta$ the model parameters. A foundation model is trained by minimizing the loss function $L$:
$$ \theta^* = \arg \min_\theta E_{(x,y) \sim D_{\text{pretrain}}} [L(f(x; \theta), y)] $$
Where $f(x; \theta)$ is the model’s prediction for input $x$.
Foundation models allow for transfer learning, which means they can be adapted to new tasks by fine-tuning on specific datasets.
2. Model Finetuning
Model fine-tuning is the process of adapting a pre-trained model to a specific task or dataset. In the context of SAM, fine-tuning refers to using a pre-trained segmentation model and adapting it for specific segmentation tasks.
For a fine-tuning dataset $D_{\text{fine}}$, the fine-tuned parameters $\theta_{\text{fine}}$ are obtained as:
$$ \theta_{\text{fine}} = \arg \min_\theta E_{(x,y) \sim D_{\text{fine}}} [L(f(x; \theta), y)] $$
This method allows SAM to adapt its general segmentation ability to specialized tasks like medical imaging or satellite image segmentation.
3. Human in the Loop (HITL) Relevance

Human-in-the-Loop (HITL) refers to involving humans at various stages of a machine learning system’s lifecycle to improve the model’s performance. In SAM, humans provide critical inputs in three main stages:
- Data Annotation: Human annotators provide ground-truth masks for training data.
- Interactive Segmentation: Users provide prompts (points, bounding boxes, scribbles) to guide SAM’s segmentation process.
- Feedback and Fine-tuning: Corrections made by users on the generated masks are fed back into the system to further fine-tune the model.
The model with human input can be represented as:
$$ M = f(I, P_{\text{human}}; \theta) $$
Where $P_{\text{human}}$ is the human prompt, $I$ is the input image, and $\theta$ are the model parameters.
4. COCO and Other Datasets

COCO (Common Objects in Context) is a large-scale dataset commonly used for segmentation, detection, and captioning tasks. It includes annotations for objects in complex scenes.
Let $\mathcal{D}_{\text{COCO}} = {(I_1, M_1), (I_2, M_2), \dots}$ represent the COCO dataset, where $I_i$ is an image and $M_i$ is the corresponding mask.
Other important datasets used in segmentation tasks include ADE20K, LVIS, and ImageNet. These datasets help train models like SAM across diverse object categories.
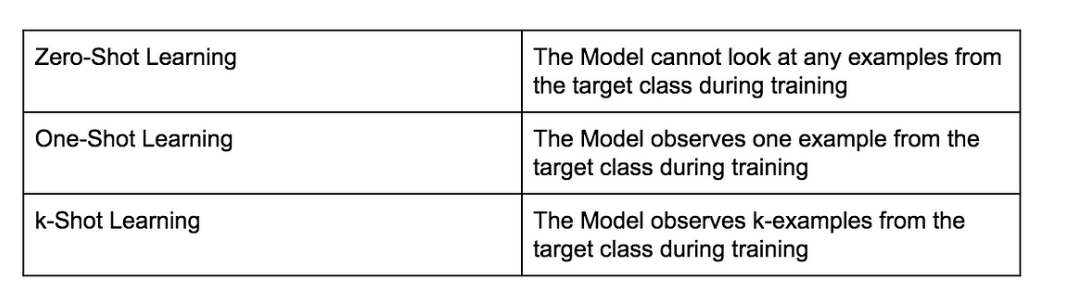
5. Zero-shot and Few-shot Learning
- Zero-shot learning refers to the model’s ability to generalize to unseen objects or tasks without any specific training examples. SAM is capable of performing zero-shot segmentation due to its extensive pre-training on diverse datasets.
For a new object $O_{\text{new}}$, the model generates a mask $M$ without specific training examples:
$$ M = f(I, O_{\text{new}}; \theta) $$
![]()
- Few-shot learning involves training a model on a small number of labeled examples. SAM can fine-tune itself on a few labeled samples and still produce accurate masks for new data.
6. FLOPs (Floating Point Operations)
FLOPs refer to the number of floating-point operations required to perform inference through the model. This gives a measure of the computational complexity of a neural network.
For a convolutional layer with input dimensions $H \times W \times C_{\text{in}}$, kernel size $K \times K$, and output channels $C_{\text{out}}$, the FLOPs can be computed as:
$$ \text{FLOPs} = H \times W \times C_{\text{in}} \times K^2 \times C_{\text{out}} $$
In a transformer model (like SAM), the self-attention mechanism contributes significantly to FLOPs. For a sequence length $N$ and embedding size $D$, the FLOPs for the self-attention mechanism is:
$$ \text{FLOPs} = 4ND^2 + 2N^2D $$
7. Edge Detection
Edge detection identifies boundaries of objects in images by detecting areas of abrupt intensity changes. This can be achieved using image gradients, for instance with the Sobel or Canny edge detectors.

For an image $I$, the gradient magnitude $G$ is computed as:
$$ G = \sqrt{\left(\frac{\partial I}{\partial x}\right)^2 + \left(\frac{\partial I}{\partial y}\right)^2} $$
Edge detection helps SAM refine the boundaries of the generated segmentation masks.
8. Ablation Studies
Ablation studies test the contribution of different components of a model by removing or altering them and measuring the effect on performance. For SAM, ablations can focus on testing different prompt types (points, bounding boxes) or removing attention layers.
The performance difference due to an ablation is quantified as:
$$ \Delta L = L_{\text{full}} - L_{\text{ablated}} $$
Where $L_{\text{full}}$ is the loss of the full model and $L_{\text{ablated}}$ is the loss of the ablated model.
9. Compositionality
Compositionality refers to the model’s ability to understand and segment complex objects composed of multiple parts. SAM’s compositionality enables it to combine segmentations of different parts into a coherent whole.
Mathematically, if $M_1$ and $M_2$ are the masks for two parts of an object, the combined mask can be expressed as:
$$ M_{\text{combined}} = M_1 \cup M_2 $$
This allows SAM to handle multi-object segmentation effectively.
10. RAI (Responsible AI) Analysis
Responsible AI (RAI) involves ensuring that AI models are developed and used ethically and fairly. In the context of SAM, RAI considerations include:
- Bias: Ensuring SAM performs equally well across different demographic groups.
- Explainability: Understanding why SAM produces specific segmentation outputs.
- Transparency: Making the model’s decisions interpretable.
Bias can be quantified by evaluating the difference in model performance across groups. Let $L_g$ be the loss for group $g$, the bias can be measured as:
$$ \text{Bias} = \max_g L_g - \min_g L_g $$
11. Compositionality
Compositionality is the ability to understand and represent complex structures made of simpler parts. For example, if $M_1$ represents the mask for object part 1 and $M_2$ the mask for part 2, the compositional segmentation of the object is:
$$ M_{\text{composite}} = M_1 \cup M_2 $$
This helps SAM handle images with multiple overlapping objects.
Limitations of SAM
While the Segment Anything Model (SAM) represents a significant advancement in image segmentation, it is important to acknowledge several limitations outlined by the authors:
-
Generalization Challenges: Although SAM aims to generalize across diverse segmentation tasks, it may still struggle with specific domains or types of images that differ significantly from the training data. For instance, tasks requiring fine-grained segmentation in specialized fields (e.g., medical imaging) might not achieve optimal performance without additional fine-tuning.
-
Sensitivity to Prompts: The performance of SAM can be highly dependent on the quality and type of prompts provided. For instance, using less informative prompts may lead to suboptimal segmentation results. The model’s effectiveness is influenced by how well the prompts convey the intended segmentation task.
-
Computational Cost: SAM’s architecture, particularly its use of Vision Transformers, can lead to high computational costs during both training and inference. This may limit its applicability in real-time scenarios or on devices with constrained computational resources.
-
Dataset Bias: The performance of SAM is contingent on the data it was trained on. While it is built on a large and diverse dataset (SA-1B), any inherent biases or limitations in this dataset can propagate into the model’s outputs, potentially affecting fairness and accuracy in various applications.
-
Lack of Fine-grained Control: While SAM is designed to handle a variety of segmentation tasks with minimal prompting, there may be scenarios where users require precise control over the segmentation process (e.g., specifying object boundaries). SAM’s generalized approach might not always provide the level of control necessary for such tasks.
-
Zero-shot Performance Variability: Although SAM exhibits impressive zero-shot capabilities, its performance can vary significantly depending on the nature of the new tasks or image distributions it encounters. In some cases, performance may not match that of fully supervised models, particularly for complex or nuanced segmentation tasks.
Sources
-
Original Paper:
- Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A. C., Lo, W.-Y., Dollár, P., & Girshick, R. (2023). Segment Anything. Meta AI.
-
Images:
- SAM Architecture Diagram: Source from Hugging Face.
- Segmentation Tasks: Source from Andlukyane.
- Semantic vs. Instance Segmentation: Source from Encord.
- Human in the Loop: Source from Levity AI
- Dice Loss: Source from Determined AI
- Responsible AI: Source from H20.AI