After releasing Trove, our inboxes and DMs flooded with questions pertaining to the underlying architecture of Trove, and most importantly, about DAaps (Decentralized Apps) and the Blockstack platform. The purpose of this post is to answer those burning questions and to take you on a journey of figuring all of this out ourselves.
The engineers @Trove have strong understanding and experience of centralized applications. We followed the decentralized space, and also built small prototypes in Blockstack and Ethereum platforms. But, Trove is our first endeavour to create a full end-to-end Decentralized Application from scratch. We had questions.
Actually, a lot of them.
Proof of Concept
A proof of concept entails investigating to be convinced of an idea. In our case, the idea was a bookmark manager. However, we also had to deep dive into the Blockstack platform to get a gist of the second part of our idea, i.e., decentralization. We started with a very very simple decentralized app.
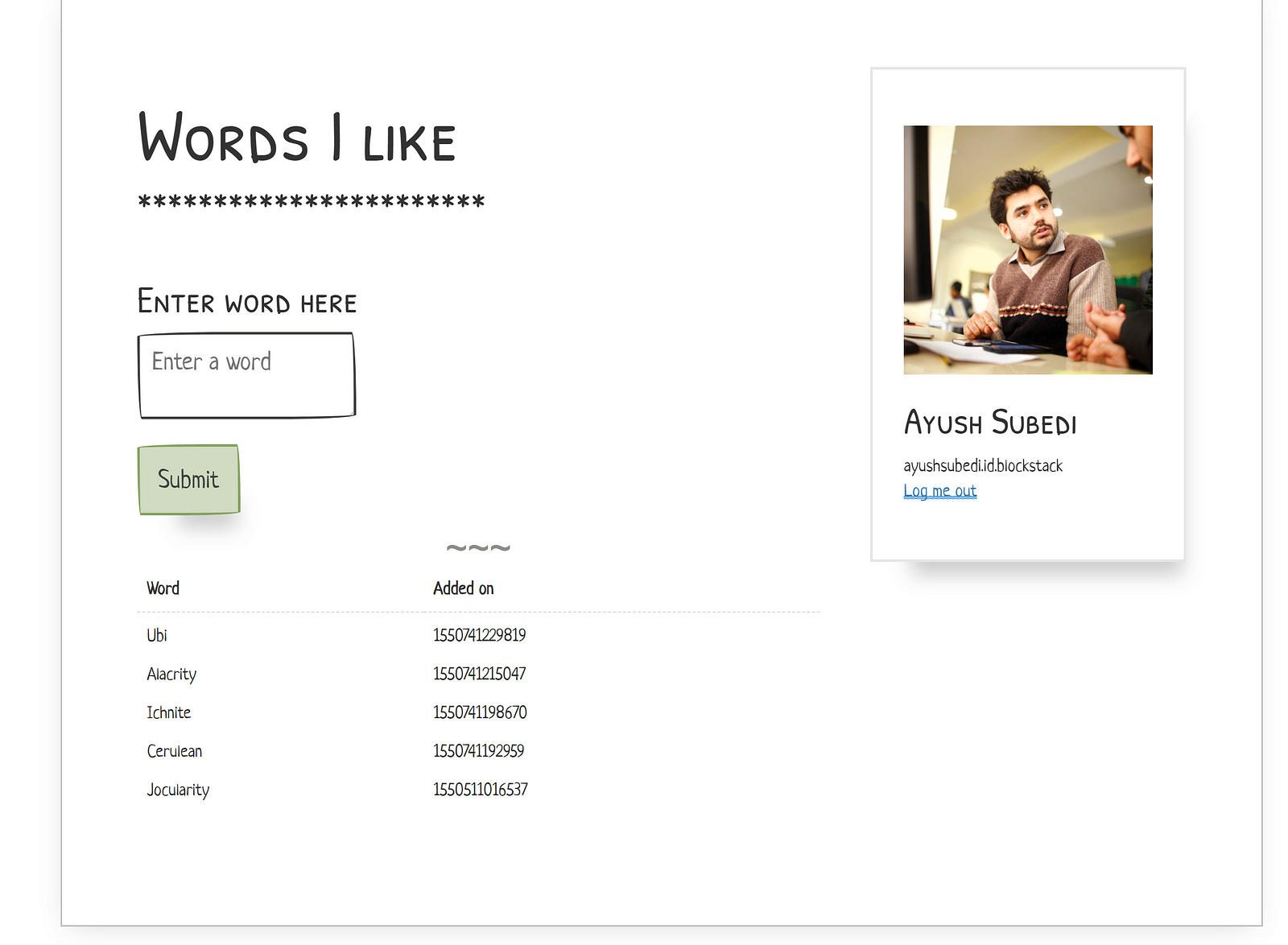
We quickly put together a decentralized app that allowed users to save their favorite words. Although the app does not make sense from a usability perspective, and might be hilarious to even think about deploying it to production, it helped answer a lot of our questions:
How will the users login/signup to use the app? The users will create an ID with Blockstack. The ID will be used to sign in all apps in the Blockstack ecosystem.
Where is the data stored? By default, when an ID is created in Blockstack, each user ID is also issued some storage space. This storage system is called Gaia. The primary purpose of Gaia is to store any relevant data for the apps that the user uses in the Blockstack ecosystem. However, Blockstack also allows users to choose their own Gaia hub and to configure the back-end provider to store data with. Learn more here.
How is the data stored in Gaia? Gaia is not a DBMS. The data for an app is stored in one or many text format files (JSON) within the app’s hub in Gaia.
Is it encrypted? This depends on the developers. The developers can choose whether or not a file should be encrypted. For our case, the words in the proof of concept app were encrypted and the bookmarks for Trove are encrypted as well.
How is it decentralized? One of the most common questions we have been receiving is regarding decentralization. Several users new to the Blockstack ecosystem have asked, “If all of my bookmarks are in the same place, how is it decentralized?”. Well, there are a few ways of thinking about this. From the perspective of the developers, all of the data pertaining to the app are scattered in several Gaia storage all over. There is no possible way for the makers of an app to have all of the data of all of the users in a centralized repository. This makes it decentralized. Also, no central repository implies no machine learning algorithm tinkering to garner patterns and trends on collective data.
Now, can we now build a MVP for our purposes? Yes. At this point, we had a better understanding of the approach to make Trove possible and optimized to leverage on Blockstack and Gaia. Moreover, we realized that a bookmark manager would be an ideal exploration for this platform because bookmarks are sacred to a specific user, and they are not normally shared. We might eventually work on the functionality of publicly shared bookmarks in the future if our users request it.
Product Specification and Minimum Viable Product
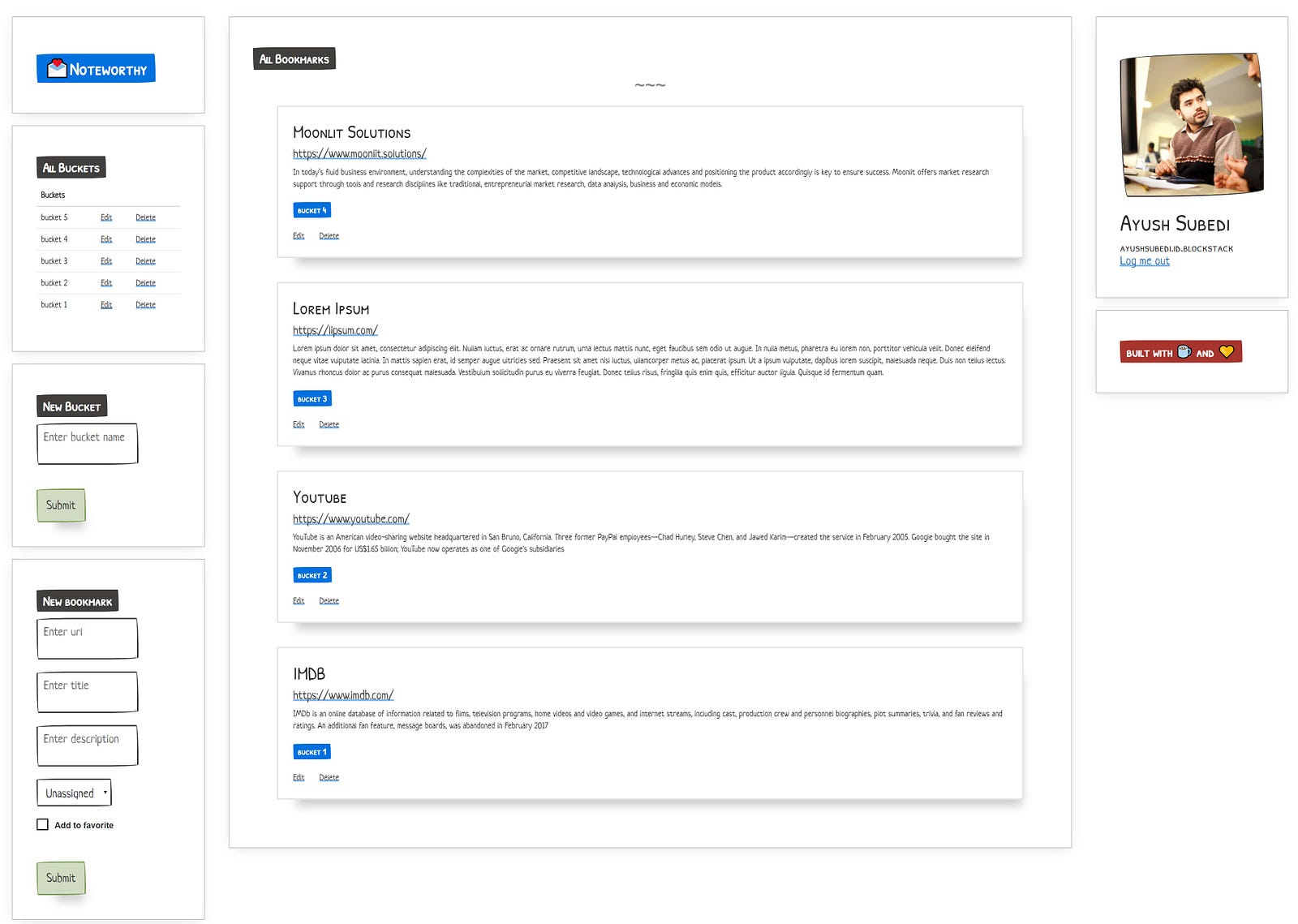
The team collectively decided to pursue these functionalities for the first version of the app:
- CRUD bookmarks
- CRUD buckets/categories for bookmarks
- CRUD tags
- Favorite bookmarks
- Archive bookmarks
- Archive buckets/categories
- Extract meta tags of bookmarks
- Extract HTML body of bookmarks for Read Mode (Parked for future version of the app)
- Extract keywords from bookmarks (Parked for future version of the app)
- Filter using buckets/categories, tags, favourites
- Search
- Browser extensions
Architecture
How are the files stored in Gaia for Trove?
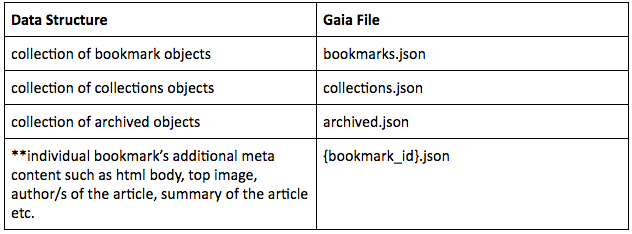
Every Trove user has three files associated with their Gaia hub to store bookmark, collections and archived objects. This schema is also backward compatible. Backward compatibility is a major issue with Gaia because schema changes in the future to incorporate any other features where we do not have access to user’s Gaia (by definition), is a major constraint and therefore needs precautions. **If we were to add Read Mode in the future (which will have massive content and makes no sense to be stored inside bookmark object anyway), it can be stored on a separate file {bookmark_id}.json and referenced with the id. This implies, in the future, a user will have 3+ files, while everything remains maintainable, compatible and scalable. A randomly generated id in base 36 (0–9, a-z) with a length of 9 is used for each category and each bookmark. The probability of collision for a user limits to 0 (1/36⁹). This decision was made so that ids can be assigned on the go without having to keep track of array sizes for incremental ids. When a bookmark is created, and assigned to a category, the bookmark object stores the id of the category and not the name. This referential association allows for seamless category name edits. For the sake of blog post brevity, we are leaving out a lot of the trivial implementation that is common with centralized architecture design pattern (archive, tags, filter, search etc). Extension
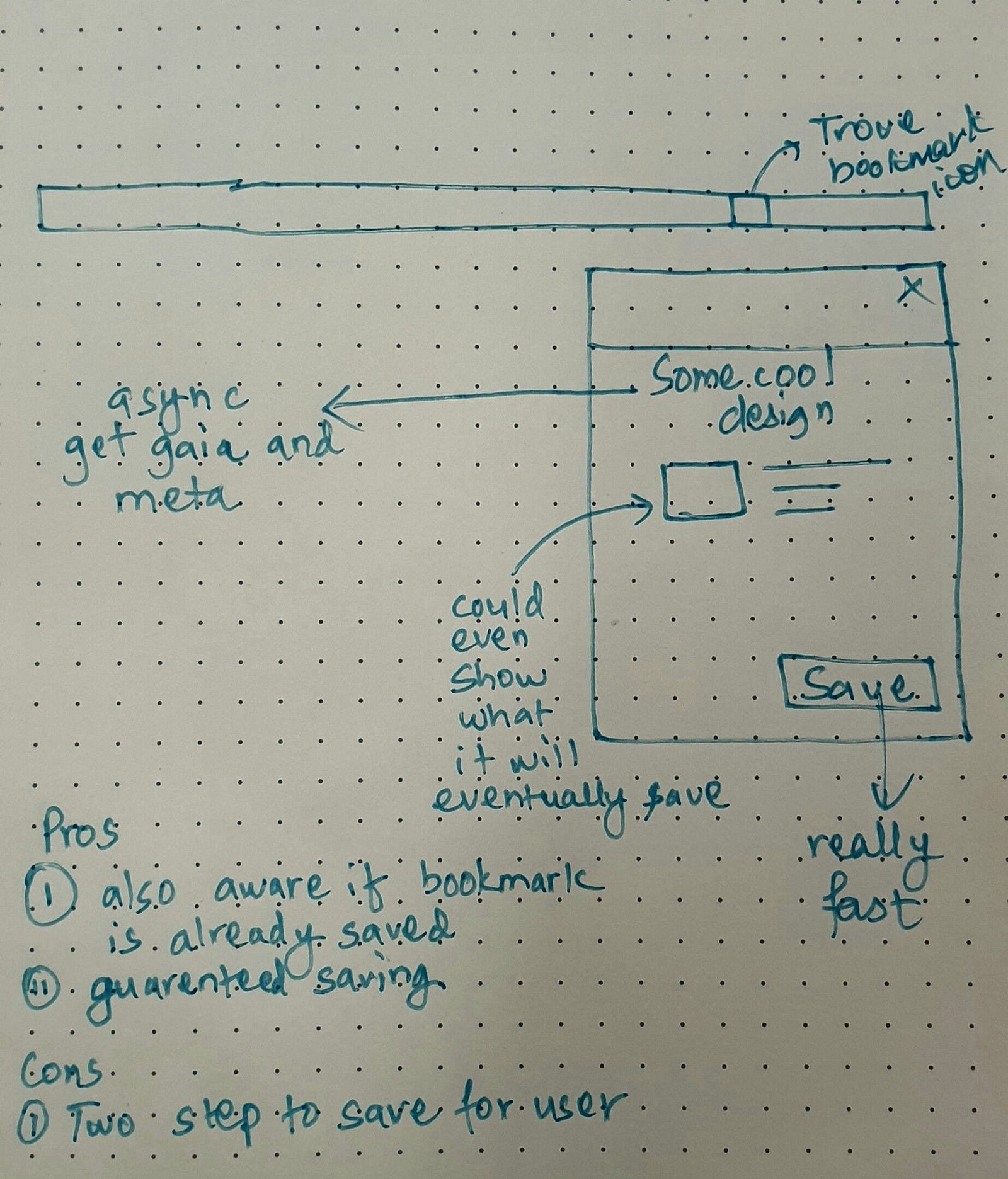
We initially started with one click bookmark save on our extension. This implied a seamless experience for the users. However, server-less comes with its limitation. In a centralized system, once the user clicked on the extension, we would have sent the URL to our back-end, scraped meta-tags and stored it in a database record referencing the user. We do not have the liberty here. The URL is sent to our open-sourced back-end for meta tag extraction, but that is all it does. It returns the response back to the extension, which does the rest. This implies a user would have to wait for a few seconds while:
- We collect meta tags from back-end
- Collect all bookmarks from Gaia
- Change 2 to an array
- Append response from back-end to the array
- Save array to Gaia as a JSON
Therefore, we decided to make it a two-step process. We are still researching on ways to make this part seamless to our users. URL Meta Extractor A simple Flask app using Newspaper package has been used for the purpose of URL extraction. The back-end extractor is open sourced at https://gitlab.com/trovenow/trovenow_url_parser. Use the app and tweet us ****for more clarification. We would love to hear your feedback. Also, please show your support by up-voting us here.
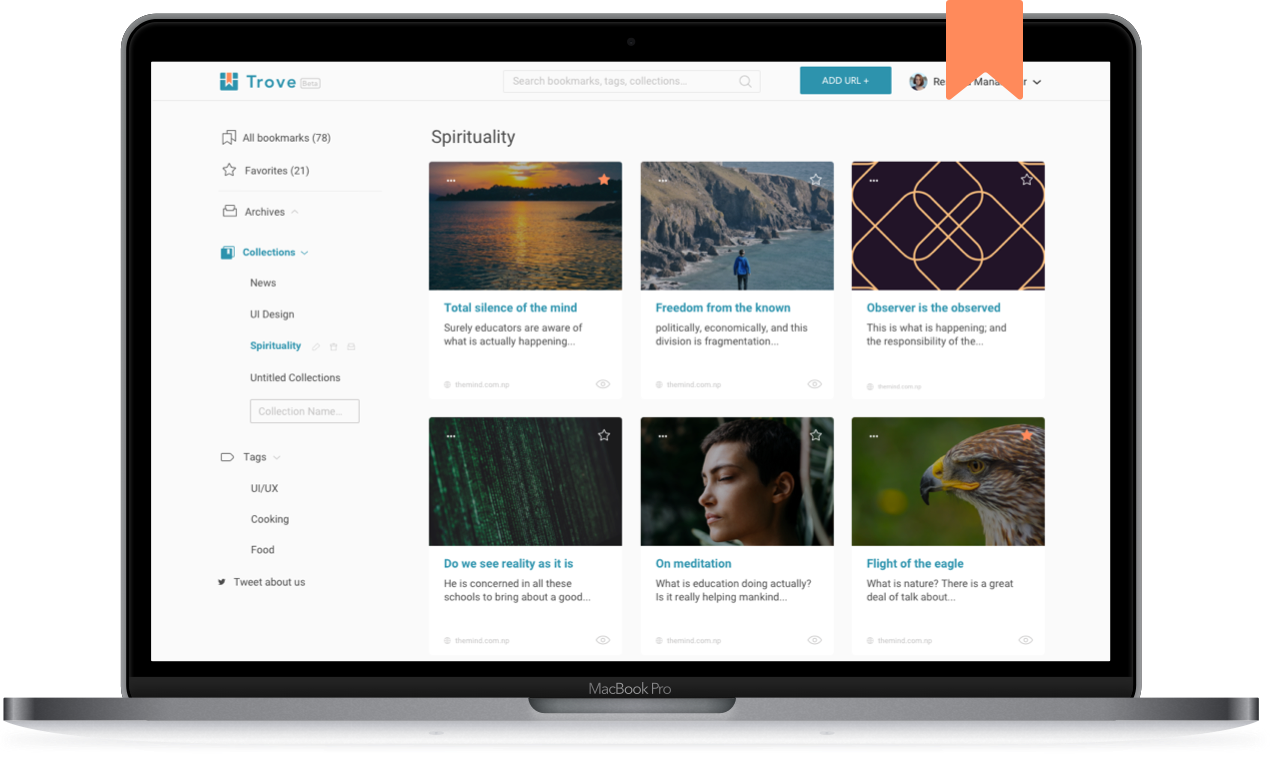
Final Version (v1) of Trove