[Paper Exploration] Train Once, Test Anywhere: Zero-Shot Learning for Text Classification
Author: Pushpankar Kumar Pushp, Muktabh Mayank Srivastava
Published on 2017
Abstract
Zero-shot Learners are models capable of predicting unseen classes. In this work, we propose a Zero-shot Learning approach for text categorization. Our method involves training model on a large corpus of sentences to learn the relationship between a sentence and embedding of sentence’s tags. Learning such relationship makes the model generalize to unseen sentences, tags, and even new datasets provided they can be put into same embedding space. The model learns to predict whether a given sentence is related to a tag or not; unlike other classifiers that learn to classify the sentence as one of the possible classes. We propose three different neural networks for the task and report their accuracy on the test set of the dataset used for training them as well as two other standard datasets for which no retraining was done. We show that our models generalize well across new unseen classes in both cases. Although the models do not achieve the accuracy level of the state of the art supervised models, yet it evidently is a step forward towards general intelligence in natural language processing.
Conclusion
In this work, we introduce techniques and models that can be used for zero-shot classification in text. We show that our models can get better than random classification accuracies on datasets without seeing even one example. We can say that this technique learns the concept of relatedness between a sentence and a word that can be extended beyond datasets. That said, the levels of accuracy leave a lot of scope for future work.
Glossary
Text Classification
The process of assigning predefined categories or labels to text documents based on their content. Common applications include sentiment analysis, spam detection, and topic categorization.

Zero-Shot Learning
A machine learning paradigm where a model is trained on certain tasks and then applied to new, unseen tasks without additional training. It leverages generalizable knowledge to perform well on tasks it has not explicitly encountered during training. (an instance og transfer learning)
from transformers import pipeline
pipe = pipeline(model="facebook/bart-large-mnli")
pipe("I have a problem with my iphone that needs to be resolved asap!",
candidate_labels=["urgent", "not urgent", "phone", "tablet", "computer"],
)
# output
>>> {'sequence': 'I have a problem with my iphone that needs to be resolved asap!!', 'labels': ['urgent', 'phone', 'computer', 'not urgent', 'tablet'], 'scores': [0.504, 0.479, 0.013, 0.003, 0.002]}
Pre-trained Language Model
A language model that has been previously trained on a large corpus of text data. Examples include BERT, GPT, and RoBERTa. These models capture rich linguistic information and can be fine-tuned for specific tasks.
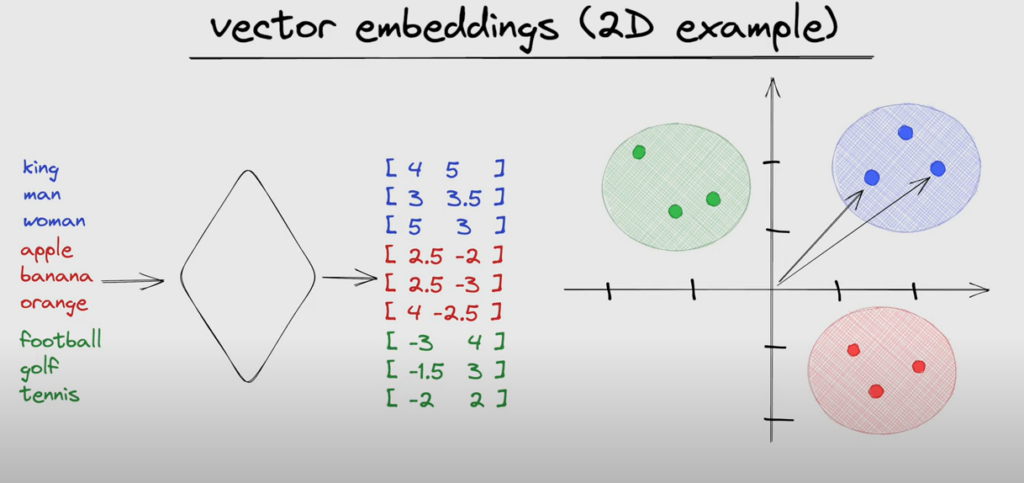
Embedding
A dense vector representation of text (words, sentences, documents) where semantically similar texts are represented by similar vectors. Embeddings are obtained using models like Word2Vec, GloVe, or BERT.
Contextual Embeddings
Embeddings that capture the meaning of a word based on its context within a sentence. Unlike static embeddings (e.g., Word2Vec), contextual embeddings vary depending on the surrounding text.
![]()
Similarity Function
A function that measures the similarity between two vectors (e.g., text embeddings). Common similarity functions include cosine similarity, Euclidean distance, and dot product.
Cosine Similarity
A measure of similarity between two non-zero vectors that calculates the cosine of the angle between them. It is defined as:
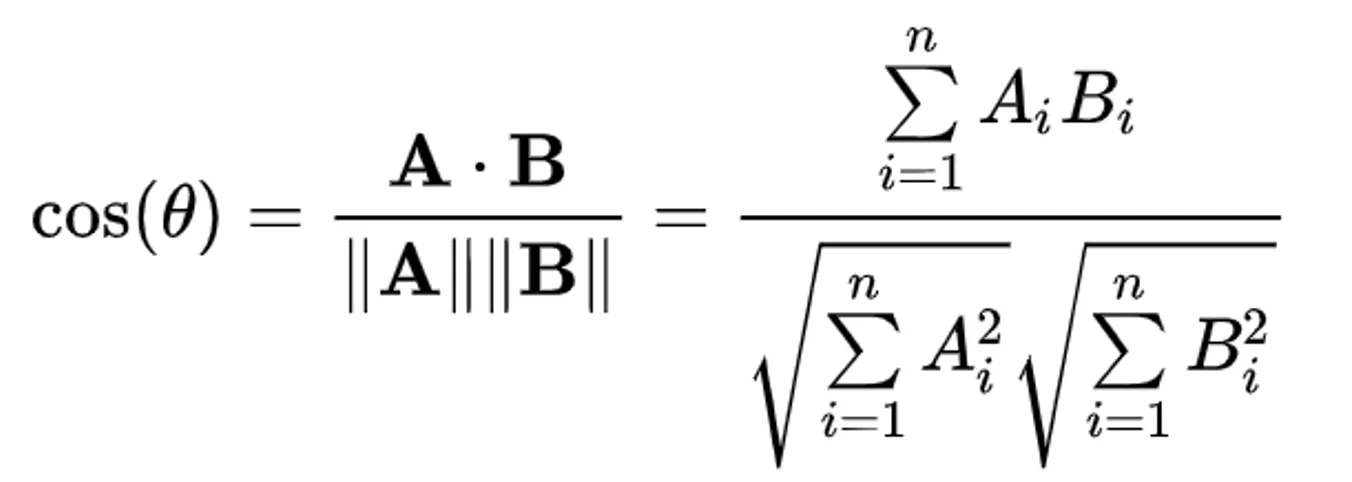
Cross-Entropy Loss
A loss function used for classification tasks. It measures the performance of a classification model whose output is a probability value between 0 and 1.
Back to Paper
Introduction
- Addresses limitations of traditional text classification models requiring large annotated datasets for each new task.
- Zero-shot learning aims to eliminate the need for task-specific training by leveraging generalizable knowledge.
Proposed Approach
- Introduces a zero-shot text classification method using pre-trained language models to classify text without task-specific fine-tuning.
- Model incorporates task descriptions (in natural language) along with input text to predict the correct class.
Methodology
Problem Definition:
- Given a set of classes $C$ and a text input $x$, assign $x$ to one of the classes in $C$ without having seen examples from $C$ during training.
Model Architecture:
- Use a pre-trained language model $\phi$ (e.g., BERT) to obtain contextual embeddings.
- For a text input $x$, the embedding is denoted as $\mathbf{h}_x = \phi(x)$.
Task Descriptions:
- Each class $ c \in C $ is associated with a natural language description $d_c$.
- The description $d_c$ is also embedded using the same pre-trained model: $\mathbf{h}_{d_c} = \phi(d_c)$.
Classification:
- Classification is based on the similarity between the embeddings of the input text $x$ and each class description $d_c$.
- A similarity function measures this similarity. Common choices include cosine similarity
Prediction:
- The predicted class $\hat{c}$ for an input $x$ is the one with the highest similarity score:
Training:
- The model learns to produce embeddings that capture the semantic content of both inputs and class descriptions.
- Training objective can be a standard classification loss, such as cross-entropy, adapted to use the similarity scores
Experiments and Results
- Evaluated on several text classification benchmarks, comparing zero-shot performance with traditional supervised learning models.
- Metrics: accuracy, precision, recall, F1-score.
- Results show competitive performance, sometimes outperforming supervised models, indicating generalization capability across tasks and domains.
Advantages
- Reduces the need for large annotated datasets for each specific task.
- Enables rapid deployment and adaptation to new tasks without additional training.
Limitations and Future Work
- Dependency on the quality of task descriptions.
- Potential reduced performance in highly specialized tasks.
- Future research includes improving task descriptions and exploring zero-shot learning for other NLP tasks.